污点分析
前言
学习该知识点的网址:https://firmianay.gitbooks.io/ctf-all-in-one/content/doc/5.5_taint_analysis.html
文章掺杂了一些个人的学习思考(不是绝对正确)
基本原理
污点分析是一种跟踪并分析污点信息在程序中流动的技术。在漏洞分析中,使用污点分析技术将所感兴趣的数据(通常来自程序的外部输入)标记为污点数据,然后通过跟踪和污点数据相关的信息的流向,可以知道它们是否会影响某些关键的程序操作,进而挖掘程序漏洞。即将程序是否存在某种漏洞的问题转化为污点信息是否会被 Sink 点上的操作所使用的问题
Eg:
1 | [...] |
污点信息不仅可以通过数据依赖传播,还可以通过控制依赖传播。我们将通过数据依赖传播的信息流称为显式信息流,将通过控制依赖传播的信息流称为隐式信息流
Eg:
1 | if (x > 0) |
变量 y 的取值依赖于变量 x 的取值,如果变量 x 是污染的,那么变量 y 也应该是污染的
对于漏洞的污点分析逻辑其实也是基于上述逻辑:
Eg:
1 | String user = getUser(); |
污点分析中,user和pass是会被标记为污点信息,污点信息进入到sql语句中,那么就会被污点分析判定为sql注入漏洞
流程大致为:
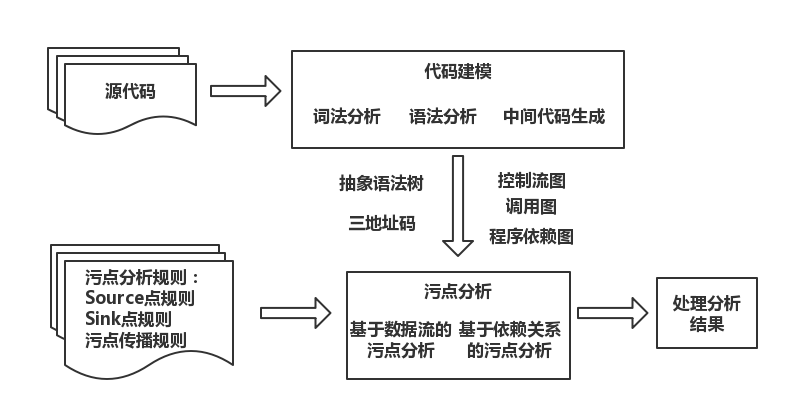
在分析过程中:
- 基于数据流的污点分析。在不考虑隐式信息流的情况下,可以将污点分析看做针对污点数据的数据流分析。根据污点传播规则跟踪污点信息或者标记路径上的变量污染情况,进而检查污点信息是否影响敏感操作
- 基于依赖关系的污点分析。考虑隐式信息流,在分析过程中,根据程序中的语句或者指令之间的依赖关系,检查 Sink 点处敏感操作是否依赖于 Source 点处接收污点信息的操作
污点分析的实现
基于数据流的污点分析实现
在基于数据流的污点分析中,常常需要一些辅助分析技术,例如别名分析、取值分析等,来提高分析精度。辅助分析和污点分析交替进行,通常沿着程序路径的方向分析污点信息的流向,检查 Source 点处程序接收的污点信息是否会影响到 Sink 点处的敏感操作
过程内的分析中,会按照一定的顺序分析过程内的每一条语句或者指令,进而分析污点信息的流向,顺序如下:
记录污点信息
在静态分析层面,程序变量的污染情况为主要关注对象。为记录污染信息,通常为变量添加一个污染标签。最简单的就是一个布尔型变量,表示变量是否被污染。更复杂的标签还可以记录变量的污染信息来自哪些 Source 点,甚至精确到 Source 点接收数据的哪一部分。当然也可以不使用污染标签,这时我们通过对变量进行跟踪的方式达到分析污点信息流向的目的。例如使用栈或者队列来记录被污染的变量
程序语句的分析
确定好污点信息,需要对程序语句进行静态分析
赋值语句
对于简单的
b=a,直接对两侧进行到相同状态的标记,而对于常量a='n11',在不考虑隐式信息流的情况下,都看作不被污染对于
a= b+c,右侧有1个被污染,则视作左侧被污染对于数组类型,本因通过数组下标进行污染标记,更准确,但是通常静态分析不能确定一个变量是被污染的,而是默认为整个数组被污染–>也可以看到其可能会存在误报
对于包含指针或者指针赋值的场景,则需要用到指针分析技术
控制转移语句
对于循环语句,通常规定循环变量的取值范围不能受到输入的影响。例如在语句
for (i = 1; i < k; i++){}中,可以规定循环的上界 k 不能是污染的对于条件控制语句,如果说对于污染变量的限制足够完整,那么该污染变量不应该被视作被污染,eg:sql语句中的参数id,本应该被识别为污染变量,如果加了一个白名单只能使用数字,那么可以说这个变量id不是污染变量
过程调用语句
可以使用过程间的分析或者直接应用过程摘要进行分析。污点分析所使用的过程摘要主要描述怎样改变与该过程相关的变量的污染状态,以及对哪些变量的污染状态进行检测。这些变量可以是过程使用的参数、参数的字段或者过程的返回值等。例如在语句
flag = obj.method(str);中,str 是污染的,那么通过过程间的分析,将变量 obj 的字段 str 标记为污染的,而记录方法的返回值的变量 flag 需要根据返回值与污染变量的相关性来判断是否被污染上述过程间分析结果不管是返回的值赋予flag是污染还是被污染,都会对其进行构建过程摘要,然后对于下次需要过程间分析时,直接分析摘要,好处是提高效率,例如一个方法会被调用上千上万次,每次都进行过程间分析,会很浪费资源,直接分析摘要,输入污染输出污染或者输入污染,返回无污染等
3.代码的遍历
流敏感
流敏感分析会按顺序追踪代码,并且在遇到赋值语句时更新变量的状态。它关心的是在代码的某一特定行上,某个变量的状态是什么
代码行 代码 流不敏感分析 (保守) 流敏感分析 (精确) L1 a = 5;a是一个常量a是 5L2 b = a;b是一个常量b是 5L3 a = userInput();a是常量或污点 (取决于起点)a现在是污点L4 print(b);无法确定 b的确切值b仍然是 5 (在 L3 赋值之前确定)路径敏感
路径敏感分析比流敏感更进一步。它不仅仅按顺序执行语句,还会跟踪并分离所有可能的执行路径,并为每条路径维护不同的变量状态
代码行 代码 流敏感分析 (保守) 路径敏感分析 (精确) L1 input = getUserInput();input是污点input是污点L2 if (input.isNumeric()) {无法确定 input的精确类型开始分离路径 L3 // 路径 A (数字)路径 A: input是已净化 (只包含数字)L4 db.query(input);可能报告漏洞 (因为 input是泛指的污点)不会报告漏洞 (因为 input在此路径是数字)L5 } else { // 路径 B (非数字)路径 B: input是污点 (包含非数字字符)L6 log.error(input);报告信息泄露 (如果 log.error是 Sink)报告信息泄露 路径敏感的分析步骤中可以看到是减少一定的误报量的
一般情况下,常常使用流敏感的方式或者路径敏感的方式进行遍历,并分析过程中的代码。如果使用流敏感的方式,可以通过对不同路径上的分析结果进行汇集,以发现程序中的数据净化规则。如果使用路径敏感的分析方式,则需要关注路径条件,如果路径条件中涉及对污染变量取值的限制,可认为路径条件对污染数据进行了净化,还可以将分析路径条件对污染数据的限制进行记录,如果在一条程序路径上,这些限制足够保证数据不会被攻击者利用,就可以将相应的变量标记为未污染的
过程间的分析与数据流过程间分析类似,使用自底向上的分析方法,分析调用图中的每一个过程,进而对程序进行整体的分析
基于依赖的污点分析实现
在基于依赖关系的污点分析中,首先利用程序的中间表示(IR)、控制流图(CFG)和过程调用图构造程序完整的或者局部的程序的依赖关系。在分析程序依赖关系后,根据污点分析规则,检测 Sink 点处敏感操作是否依赖于 Source 点
分析程序依赖关系的过程可以看做是构建程序依赖图的过程。程序依赖图是一个有向图。它的节点是程序语句,它的有向边表示程序语句之间的依赖关系。程序依赖图的有向边常常包括数据依赖边和控制依赖边。在构建有一定规模的程序的依赖图时,需要按需地构建程序依赖关系,并且优先考虑和污点信息相关的程序代码。
Eg:
1 | // L1 |
其程序依赖图(抽象图示):
| 语句 | 数据依赖于… | 控制依赖于… |
|---|---|---|
L1: username = ... |
无 | 无 (入口节点) |
L2: filteredName; |
无 | 无 |
L3: if (...) |
L1 | 无 |
L4: filteredName = sanitize(...); |
L3 (条件)、L1 (数据) | L3 (if 条件为真) |
L5: filteredName = "Guest"; |
L3 (条件) | L3 (if 条件为假) |
L6: query = ... + filteredName |
L4 或 L5 | 无 (在 if 之外) |
L7: db.execute(query); |
L6 | 无 |
目标: 检测 Sink (L7) 是否依赖于 Source (L1)。
PDG 分析的强大之处在于它的反向分析(切片)和按需构建:
PDG 允许分析器从 Sink 点(L7)开始,逆着依赖边往回追踪:
- 从 Sink L7 开始:
db.execute(query)依赖于query(L6)。 - 追踪 L6:
query(L6) 依赖于filteredName(L4 和 L5)。 - 追踪 L4 和 L5 (数据依赖):
- L5 路径:
filteredName = "Guest"。这是一个安全常量。此路径终止。 - L4 路径:
filteredName = sanitize(username)。
- L5 路径:
- 追踪 L4 (数据和控制依赖): L4 依赖于
username(L1) 和 L3 (控制条件)。 - 追踪 L1: L1 是
Source
如果程序有 1000 个函数,但 L7 只使用了 3 个函数中的变量,PDG 分析器会只构建这 3 个函数所涉及的依赖图,忽略其他 997 个不相关的函数,从而极大地提高分析效率。
动态污点分析
动态污点标记
污点数据通常主要是指软件系统所接受的外部输入数据,在计算机中,这些数据可能以内存临时数据的形式存储,也可能以文件的形式存储。当程序需要使用这些数据时,一般通过函数或系统调用来进行数据访问和处理,因此只需要对这些关键函数进行监控,即可得到程序读取或输出了什么污点信息。另外对于网络输入,也需要对网络操作函数进行监控。
识别出污点数据后,需要对污点进行标记。污点生命周期是指在该生命周期的时间范围内,污点被定义为有效。污点生命周期开始于污点创建时刻,生成污点标记,结束于污点删除时刻,清除污点标记。
- 污点创建
- 将来自于非可靠来源的数据分配给某寄存器或内存操作数时
- 将已经标记为污点的数据通过运算分配给某寄存器或内存操作数时
- 污点删除
- 将非污点数据指派给存放污点的寄存器或内存操作数时
- 将污点数据指派给存放污点的寄存器或内存地址时,此时会删除原污点,并创建新污点
- 一些会清除污点痕迹的算数运算或逻辑运算操作时
污点动态跟踪
当污点数据从一个位置传递到另一个位置时,则认为产生了污点传播。污点传播规则:
| 指令类型 | 传播规则 | 举例说明 |
|---|---|---|
| 拷贝或移动指令 | T(a)<-T(b) | mov a, b |
| 算数运算指令 | T(a)<-T(b) | add a, b |
| 堆栈操作指令 | T(esp)<-T(a) | push a |
| 拷贝或移动类函数调用指令 | T(dst)<-T(src) | call memcpy |
| 清零指令 | T(a)<-false | xor a, a |
注:T(x) 的取值分为 true 和 false 两种,取值为 true 时表示 x 为污点,否则 x 不是污点。
对于污点信息流,通过污点跟踪和函数监控,已经能够进行污点信息流流动方向的分析。但由于缺少对象级的信息,仅靠指令级的信息流动并不能完全给出要分析的软件的确切行为
Eg:
| 语句 ID | 代码/指令 | 污点追踪结果 |
|---|---|---|
| L1 | handle = open(path, mode) |
path 是用户输入(污点) |
| L2 | data = read(handle) |
data 的污点状态从 handle 继承 |
| L3 | socket.send(data) |
data 是污点,流入网络 Sink |
仅靠指令级流动分析,会得出结论: 用户控制的 path 最终影响了网络传输的 data,存在路径穿越漏洞或信息泄露
但这个结论可能是不准确的,因为我们缺少关于 handle(文件对象)和 socket(套接字对象)的完整状态
- 对于
handle(文件对象):- 指令级只知道: 它是一个文件句柄。
- 对象级信息缺失: 我们不知道这个文件句柄是什么文件。
- 如果是
handle = open("/etc/passwd", "r"),那么 L3 的行为是巨大的信息泄露。 - 如果是
handle = open("/tmp/log.txt", "w"),而日志文件内容是程序内部生成的,那么 L3 的行为可能只是正常日志发送。
- 如果是
- 结论: 缺少文件路径和权限这个“对象级信息”,我们无法准确评估风险。
- 对于
socket(套接字对象):- 指令级只知道: 数据被发送到网络。
- 对象级信息缺失: 我们不知道这个套接字连接到哪里。
- 如果是连接到外部攻击者的 IP/端口,那么 L3 的行为是命令执行结果回传(严重的 RCE)。
- 如果是连接到
127.0.0.1:8080(即本地内部服务),那么 L3 的行为可能只是正常的内部服务间通信。
- 结论: 缺少远程 IP 地址和端口这个“套接字对象的详细信息”,我们无法判断是否存在 SSRF 或 RCE 风险。
根据漏洞分析的实际需求,污点分析应包括两方面的信息:
- 污点的传播关系,对于任一污点能够获知其传播情况
- 对污点数据进行处理的所有指令信息,包括指令地址、操作码、操作数以及在污点处理过程中这些指令执行的先后顺序等
根据动态跟踪的实现通常使用:
Eg:监控以下C/C++伪代码
1 | // L1: 用户输入,被标记为污点源 |
- 影子内存:真实内存中污点数据的镜像,用于存放程序执行的当前时刻所有的有效污点
| 真实内存地址 (假设) | 真实内存内容 | 影子内存地址 | 影子内存内容 (污点标签) |
|---|---|---|---|
0x1000 |
'A' |
0x2000 |
Taint ID (如 #1) |
0x1001 |
'B' |
0x2001 |
Taint ID (如 #1) |
0x1002 |
'\0' |
0x2002 |
Clean (干净) |
0x1003 |
... |
0x2003 |
Clean (干净) |
对应示例:
- L1 (
input = GetUserInput();)**:当用户输入的数据(假设存放在0x1000开始的内存)进入程序时,DTA 系统会立即在对应的影子内存区域(假设0x2000开始)标记上一个唯一的污点 ID (#1)**。 - L2 (
strcpy(buffer, input);)**:当数据从input拷贝到buffer时,DTA 系统会检查input的影子内存,发现其有污点 ID #1。于是,它将这个污点 ID 复制到buffer对应内存的影子内存**中。
作用: 影子内存提供了一个即时、高效的查询机制,用于判断任何内存位置的数据在当前时刻是否被污染。
- 污点传播树:一种树形结构,记录污点数据从 Source 到 Sink 的整个衍变和传播路径。它记录了污点的来源和传递关系。
对应示例:
当污点从一个变量传递到另一个变量时,传播树的节点就会增加,记录这个“谁来自谁”的关系。
根节点: Taint ID #1 (来自
GetUserInput())第一次传播 (L2): 节点 #2 (变量
buffer) 的污点来自 Taint ID #1。
- 树结构:
Taint #1$\rightarrow$Buffer
- 第二次传播 (L3): 节点 #3 (变量
query) 的污点来自buffer。
- 树结构:
Taint #1$\rightarrow$Buffer$\rightarrow$Query
作用:如果在 Sink 点(L4)发现 query 是污点,可以通过回溯传播树,立即确定原始污点源是哪个 GetUserInput() 调用,以及中间经过了哪些变量。这对于生成漏洞报告至关重要
- 污点处理指令链:按时间顺序,记录所有涉及污点数据操作的指令序列。它记录了污点在传播过程中被处理的操作历史
对应示例:
| 顺序 | 指令地址 (或 L 编号) | 操作类型 | 污点数据 | 描述 |
|---|---|---|---|---|
| 1 | L1 | Source | input |
污点源,ID #1 |
| 2 | L2 | Copy | strcpy |
污点从 input $\rightarrow$ buffer |
| 3 | L3 | Combine | sprintf |
污点与干净数据合并 $\rightarrow$ query |
| 4 | L4 | Sink | ExecuteSQL |
污点流入敏感函数 |
作用:
- 检测净化函数: 如果在指令链中发现
sanitize(buffer)这样的指令,分析器可以判断这是一个净化操作。它会检查该操作是否足以清除污点。 - 漏洞证据: 指令链提供了漏洞利用的确切执行路径和操作序列。例如,如果
ExecuteSQL依赖于query,指令链清晰地展示了query是如何一步步被用户输入构建起来的
以上三种机制是一个完整的 DTA(Dynamic Taint Analysis) 追踪系统
当遇到会引起污点传播的指令时,首先对指令中的每个操作数都通过污点快速映射查找影子内存中是否存在与之对应的影子污点从而确定其是否为污点数据,然后根据污点传播规则得到该指令引起的污点传播结果,并将传播产生的新污点添加到影子内存和污点传播树中,同时将失效污点对应的影子污点删除。同时由于一条指令是否涉及污点数据的处理,需要在污点分析过程中动态确定,因此需要在污点处理指令链中记录污点数据的指令信息
动态污点实例分析
Eg:检测缓冲区溢出漏洞
1 | void fun(char *str) |
程序接受外部输入字符串的二进制代码如下:
1 | 0x08048609 <+51>: lea eax,[ebp-0x2a] |
程序调用 strncpy 函数的二进制代码如下:
1 | 0x080485a1 <+59>: push DWORD PTR [ebp-0x2c] |
首先,在扫描该程序的二进制代码时,能够扫描到 call <gets@plt>,该函数会读入外部输入,即程序的攻击面。确定了攻击面后,我们将分析污染源数据并进行标记,即将 [ebp-0x2a] 数组(即源程序中的source)标记为污点数据。程序继续执行,该污染标记会随着该值的传播而一直传递。在进入 fun() 函数时,该污染标记通过形参实参的映射传递到参数 str 上。然后运行到 Sink 点函数 strncpy()。该函数的第二个参数即 str 和 第三个参数 strlen(str) 都是污点数据。最后在执行 strncpy() 函数时,若设定了相应的漏洞规则(目标数组小于源数组),则漏洞规则将被触发,检测出缓冲区溢出漏洞
